Asynchronous Rust for fun & profit
Posted on Fri 28 April 2017 in Programming
…or: Is Rust webscale?
In this day and age, no language can really make an impact anymore unless it enables its programmers to harness the power of the Internet. Rust is no different here. Despite posing as a true systems language (as opposed to those only marketed as such), it includes highly scalable servers as a prominent objective in its 2017 agenda.
Presumably to satisfy this very objective, the Rust ecosystem has recently seen some major developments in the space of asynchronous I/O. Given the pace of those improvements, it may seem that production quality async services are quite possible already.
But is that so? How exactly do you write async Rust servers in the early to mid 2017?
To find out, I set to code up a toy application. Said program was a small intermediary/API server (a “microservice”, if you will) that tries to hit many of the typical requirements that arise in such projects. The main objective was to test the limits of asynchronous Rust, and see how easily (or difficult) they can be pushed.
This post is a summary of all the lessons I’ve learned from that.
It is necessarily quite long, so if you look for some TL;DR, scroll down straight to Conclusions.

Asynchro-what?
Before we dive in, I have to clarify what “asynchronous” means in this context. Those familiar with async concepts can freely skip this section.
Pulling some threads
Asynchronous processing (or async for short) is brought up most often in the context of I/O operations: disk reads, network calls, database queries, and so on.
Relatively speaking, all those tasks tend to be slow: they take orders of magnitude longer than just executing code or even accessing RAM. The “traditional” (synchronous) approach to dealing with them is to relegate those tasks to separate threads.
When one thread has to wait for a lengthy I/O operation to complete, the operating system (its scheduler, to be precise) can suspend that thread. This lets others execute their code in the mean time and not waste CPU cycles.
This is the essence of concurrency1.
Schedule yourself
But threads are not the only option when dealing with many things (i.e. requests) at once.
The alternative approach is one where no threads are automatically suspended or resumed by the OS. Instead, a special version of I/O subroutines allows the program to continue execution immediately after issuing an I/O call. While the operation happens in the background2, the code is given an opaque handle — usually called a promise, a future, or an async result — that will eventually resolve to the actual return value.
The program can wait for the handle synchronously, but it would typically hand it over to an event loop, an abstraction provided by a dedicated async framework. Such a framework (among which node.js is probably the best known example) maintains a list of all I/O “descriptors” (fds in Unix) that are associated with pending I/O operations.
Then, in the loop, it simply waits on all of them,
usually via the epoll system call.
Whenever an I/O task completes, the loop would execute a callback associated
with its result (or promise, or future).
Through this callback, the application is able to process it.
In a sense, we can treat the event loop as a dedicated scheduler for its program.
But why?
So, what exactly the benefit of asynchronous I/O? If anything, it definitely sounds more complicated for the programmer. (Spoiler alert: it is).
The impetus for the development of async techniques most likely came from the C10K problem. The short version of it is that computers are nowadays very fast and should therefore be able to serve thousands of requests simultaneously. (especially when those requests are mostly I/O, which translate to waiting time for the CPU).
And if “serving” queries is indeed almost all waiting, then handling thousands of clients should be very possible.
In some cases, however, it was found that when the OS is scheduling the threads,
it introduces too much overhead on the frequent pause/resume state changes (context switching).
Like I mentioned above, the asynchronous alternative does away with all that,
and indeed lets the CPU just wait (on epoll) until something interesting happens.
Once it does, the application can deal with it quickly,
issue another I/O call, and let the server go back to waiting.
With today’s processing power we can theoretically handle a lot of concurrent clients this way: up to hundreds of thousands or even millions.
Reality check
Well, ain’t that grand? No wonder everyone is writing everything in node.js now!
Jokes aside, the actual benefits of asynchronous I/O (especially when weighed against its inconvenience for developers) are a bit harder to quantify. For one, they rely heavily on the assumption of fast code & slow I/O being valid in all situations.
But this isn’t really self-evident, and becomes increasingly dubious as time goes on and code complexity grows. It should be obvious, for example, that a Python web frontend talking mostly to in-memory caches in the same datacenter will have radically different performance characteristics than a C++ proxy server calling HTTP APIs over public Internet. Those nuances are often lost in translation between simplistic benchmarks and exaggerated blog posts3.
Upon a closer look, however, these details point quite clearly in favor of asynchronous Rust. Being a language that compiles to native code, it should usually run faster than interpreted (Python, Ruby) or even JITed (JVM & .NET) languages, very close to what is typically referred to as “bare metal” speed. For async I/O, it means the event loop won’t be disturbed for a (relatively) long time to do some trivial processing, leading to higher potential throughput of requests.
All in all, it would seem that Rust is one of the few languages where async actually makes sense.
Rust: the story so far
Obviously, this means it’s been built into the language right from the start… right?
Well, not really.
It was always possible to use native epoll through FFI,
of course, but that’s not exactly the level of abstraction we’d like to work with.
Still, the upper layers of the async I/O stack have been steadily growing at least since Rust 1.0.
The major milestones here include mio,
a comparatively basic building block that provides an asynchronous version of TCP/IP.
It also offers idiomatic wrappers over epoll, allowing us to write our own event loop.
On the application side, the futures crate abstracts the notion of a potentially incomplete operation into, well, a future. Manipulating those futures is how one can now write asynchronous code in Rust.
More recently, Tokio has been emerging as defacto framework for async I/O in Rust. It essentially combines the two previously mentioned crates, and provides additional abstractions specifically for network clients and servers.
And finally, the popular HTTP framework Hyper is now also supporting asynchronous request handling via Tokio. What this means is that bread-and-butter of the Internet’s application layer — API servers talking JSON over HTTP — should now be fully supported by the ecosystem of asynchronous Rust.
Let’s take it for a spin then, shall we?
The Grand Project
Earlier on, we have established that the main use case for asynchronous I/O is intermediate microservices. They often sit somewhere between a standard web frontend and a storage server or a database. Because of their typical role within a bigger system, these kinds of projects don’t tend to be particularly exciting on their own.
But perhaps we can liven them up a little.
In the end, it is all about the Internet that we’re talking here, and everything on the Internet can usually be improved by one simple addition.

…Okay, two possible additions — the other one being:

If you’re really pedantic, you may call them image macros. But regardless of the name, the important part is putting text on pictures, preferably in a funny way.
The microservice I wrote is doing just that. Thought it won’t ensure your memes are sufficiently hilarious, it will try to deliver them exactly to your specifications. You may thus think of it as possible backend for an image site like this one.
Flimsy excuses & post-hoc justifications
It is, of course, a complete coincidence, lacking any premeditation on my part, that when it comes to evaluating an async platform, a service like this fits the bill very well.
And especially when said platform is async Rust.
Why, though, is it such a happy, er, accident?
-
It’s a simple, well-defined application. There is basically a single endpoint, accepting simple input (JSON or query string) and producing a straightforward result (an image). No need to persist any state made creating an MVP significantly easier.
-
Caching can be used for meme templates and fonts. Besides being an inherent part of most network services, a cache also represents a point of contention for Rust programs. The language is widely known for its alergy to global mutable state, which is exactly what programmatic caches boil down to.
-
Image captioning is a CPU-intensive operation. While the “async” part of async I/O may sometimes go all the way down, many practical services either evolve some important CPU-bound code, or require it right from the start. For this reason, I wanted to check if & how async Rust can mix with threaded concurrency.
-
Configuration knobs can be added. Unlike trivial experiments in the vein of an echo or “Hello world” server, this kind of service warrants some flags that the user could tweak, like the number of image captioning threads, or the size of the template cache. We can see how easy (or how hard) it is to make them applicable across all future-based requests.
All in all, and despite its frivolous subject matter, a meme server is actually hitting quite a few notable spots in the microservice domain.

Learnings
As you may glean from its GitHub repo, it would seem that the experiment was successful. Sure, you could implement some features in the captioning department (supporting animated GIFs comes to mind), but none of these are pertinent to the async mechanics of the server.
And since it’s the async (I/O) in Rust that we’re interested in, let me now present you with an assorted collection of practical experiences with it.
>0-cost futures
If you read the docs’ preamble to the futures crate,
you will see it mentioning the “zero-cost” aspect of the library.
Consistent with the philosophy behind Rust,
it proclaims to deliver its abstractions without any overhead.
Thing is, I’m not sure how this promise can be delivered on in practice.
Flip through the introductory tutorial to Tokio,
for example, and you will already find plenty of compromises.
Without the crucial (but nightly-only)
impl Trait feature,
you are basically required to put all your futures in a Box4.
They even encourage it themselves, offering a convenient
Future::boxed method
exactly for this purpose, as well the matching
BoxFuture typedef
right in the crate.
But hey, you can always just use nightly Rust, right?
impl Trait will stabilize eventually, so your code should be, ahem, future-proof either way.
Unfortunately, this assumes all the futures that you’re building your request handlers from
shall never cross any thread boundaries.
(BoxFuture, for example, automatically constrains them to be Send).
As you’ve likely guessed, this doesn’t jive very well with computationally intensive tasks
which are best relegated to a separate thread.
To deal with them properly, you’re going to need a thread pool-based executor,
which is currently implemented in the futures_cpupool crate.
Using it requires a lot of care, though,
and a deep understanding of both types of concurrency involved.
Evidently, this was something that I lacked at the time,
which is why I encountered problems ensuring that my futures are properly Send.
In the end, I settled on making them Send in the most straightforward
(and completely unnecessary) manner:
by wrapping them in Arc/Mutex.
That in itself wasn’t
without its perils,
but at least allowed me to move forward.
Ironically, this also shows an important, pragmatic property of the futures’ system: sub-par hacks around it are possible — a fact you’ll be glad to know about on the proverbial day before a deadline.
Templates-worthy error messages
Other significant properties of the futures’ abstraction shall include telling the programmer what’s wrong with his code in the simplest, most straightforward, and concise manner possible.
Here, let me show you an example:
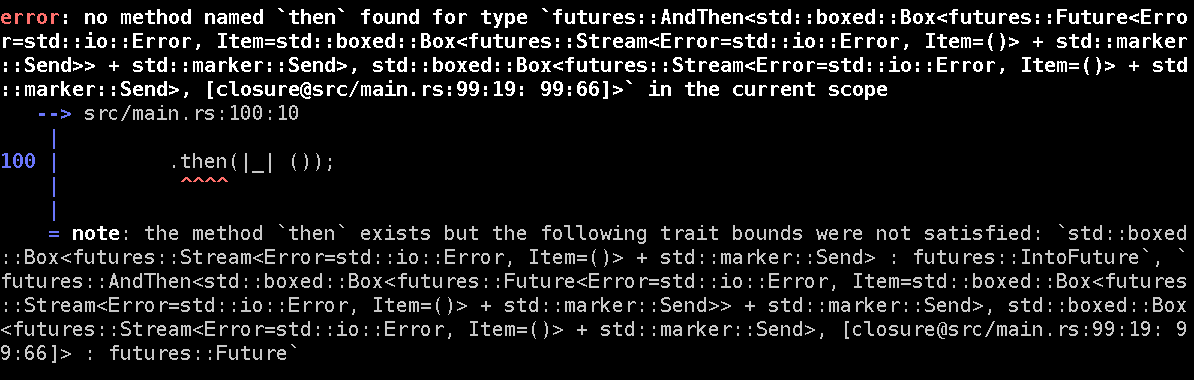
…which you can also behold in its
gist form
.
The reason you will encounter such incomprehensible messages stems from the very building blocks of async code.
Right now, each chained operation on a future — map, and_then, or_else, and so on —
produces a nested type.
Every subsequent application of those methods
“contains” (in terms of the type system) all the previous ones.
Keep going, and it will eventually balloon into one big onion of Chain<Map<OrElse<Chain<Map<...etc...>>>>>.

Futures are like ogres.
I haven’t personally hit any compiler limits in this regard, but I’m sure it is plausible for a complicated, real-world program.
It also gets worse if you use nightly Rust with impl Trait.
In this case, function boundaries no longer “break” type stacking
via Boxing the results into trait objects.
Indeed, you can very well end up with some truly gigantic constructs
as the compiler tries represent the return types of your most complex handlers.
But even if rustc is up to snuff and can deal with those fractals just fine, it doesn’t necessarily mean the programmer can. Looking at those error messages, I had vivid flashbacks from hacking on C++ templates with ancient compilers like VS2005. The difference is, of course, that we’re not trying any arcane metaprogramming here; we just want to do some relatively mundane I/O.
I have no doubt the messaging will eventually improve, and the mile-long types will at least get pretty-printed. At the moment, however, prepare for some serious squinting and bracket-counting.
Where is my (language) support?
Sadly, those long, cryptic error messages are not the only way in which the Rust compiler disappoints us.
I keep mentioning impl Trait as a generally desirable language feature
for writers of asynchronous code.
This improvement is still a relatively long way from getting precisely
defined,
much less stabilized.
And it is only a somewhat minor improvement in the async ergonomics.
The wishlist is vastly longer and even more inchoate.
Saying it bluntly, right now Rust doesn’t really support the async style at all. All the combined API surface of futures/Tokio/Hyper/etc. is a clever, but ultimately contrived design, and it has no intentional backing in the Rust language itself.
This is a stark contrast with numerous other languages.
They often support asynchronous I/O as something of a first class feature.
The list includes at least
C#,
Python 3.5+,
Hack/PHP,
ES8 / JavaScript,
and basically all the functional languages.
They all have dedicated async, await, or equivalent constructs
that make the callback-based nature of asynchronous code essentially transparent.
The absence of similar support puts Rust in the same bucket as frontend JavaScript circa 2010,
where .then-chaining of promises reigned supreme.
This is of course better than the callback hell of early Node,
but I wouldn’t think that’s a particularly high bar.
In this regard, Rust leaves plenty to be desired.
There are proposals,
obviously, to bring async coroutines into Rust.
There is an even broader wish to make the language cross the OOP/FP fence already
and commit to the functional way; this would mean adding an equivalent of Haskell’s do notation.
Either development could be sufficient. Both, however, require significant amount of design and implementation work. If solved now, this would easily be the most significant addition to the language since its 1.0 release — but the solution is currently in the RFC stages at best.
Future<Ecosystem>
While the core language support is lacking, the great as usual Rust community has been picking up some of the slack by establishing and cultivating a steadily growing ecosystem.
The constellation of async-related crates clusters mostly around the two core libraries:
futures crate itself and Tokio.
Any functionality you may need while writing asynchronous should likely be found
quite easily by searching for one of those two keywords (plus Rust, of course).
Another way of finding what you need is to look at
the list of Tokio-related crates directly.
To be fair, I can’t really say much about the completeness of this ecosystem. The project didn’t really require too many external dependencies — the only relevant ones were:
futures_cpupoolmentioned beforetokio-timerfor imposing a timeout on caption requeststokio-signalwhich handles SIGINT/Ctrl+C and allows for a graceful shutdown
Normally, you’d also want to research the async database drivers for your storage system of choice. I would not expect anything resembling the Diesel ORM crate, though, nor a web framework comparable to Iron, Pencil, or Rocket.
Conclusions
Alright, so what can we get from this overall analysis?
Given the rapid development of async Rust ecosystem so far, it is clear the technology is very promising. If the community maintains its usual enthusiasm and keeps funneling it into Tokio et al., it won’t be long before it matures into something remarkable.
Right now, however, it exposes way too many rough edges to fully bet on it. Still, there may be some applications where you could get away with an async Rust backend even in production. But personally, I wouldn’t recommend it outside of non-essential services, or tools internal to your organization.
If you do use async Rust for microservices, I’d also advise to take steps to ensure they remain “micro”. Like I’ve elaborated in the earlier sections, there are several issues that make future-based Rust code scale poorly with respect to maintainability. Keeping it simple is therefore essential.
To sum up, async Rust is currently an option only for the adventurous and/or small. Others should stick to a tried & tested solution: something like Java (with Quasar), .NET, Go, or perhaps node.js at the very least.
-
It is also the crux of parallelism, but that’s different and is not the focus here. ↩
-
“Background” here refers to the low level, innate concurrency of the OS kernel (mediated with hardware interrupts), not the
epoll-based event loops on the application side. ↩ -
There is a great parallel to be drawn between a trivial echo/Hello world server, and a 3D graphics program that only redraws an empty screen. Both may start at some very high performance numbers (requests/frames per second) but once you start adding practical stuff, those metrics must drop hyperbolically. ↩
-
Technically, you are not, but the alternative is extremely cumbersome.
In short, you’d have to follow an approach similar to customIterators: define a new struct for each individual case (possibly just newtype‘ing an existing one), and then implement the necessary trait for it.
For iterators, this works reasonably well, and you don’t need custom ones that often anyway. But futures, by their very nature, are meant to encapsulate any computation. For them, “each individual case” is literally every asynchronous function in your code. ↩